Key Takeaways:
- AI DocNexus extracts structured data from 200+ document formats across 50+ languages with 95%+ field-level accuracy.
- Template-free: handles new document layouts without configuration, unlike rules-based legacy IDP tools.
- Native unstructured document support via LLM-based semantic extraction (contracts, clinical notes, free-form claims).
- Pre-built connectors for SAP, Oracle, Salesforce, Guidewire, Epic, ServiceNow, plus REST API and webhooks.
- Deployment options: SaaS, private cloud (AWS/Azure/GCP), fully on-premise and air-gapped.
- SOC 2 Type II, HIPAA, and GDPR compliant with regional data residency (US, EU, UK, India, APAC).
- Typical ROI: 60–80% data-entry cost reduction; positive ROI by month 6, 3–5x return by month 18.
Enterprise operations still run on documents. Invoices, contracts, claims forms, shipping papers, KYC packages, medical records — every workflow that moves money, risk, or decisions is gated by someone reading a document and typing its contents into a system. Industry benchmarks consistently show knowledge workers spend 30–50% of their time on document handling, and most large enterprises quietly carry $10M–$100M+ in annual data-entry and manual-review costs.
AI DocNexus, the AI document parsing platform by AgenticSwift, automates this work end-to-end — from document intake through structured data delivery into your core systems. This guide covers what AI DocNexus does, how it works, what it integrates with, and how enterprises deploy it.
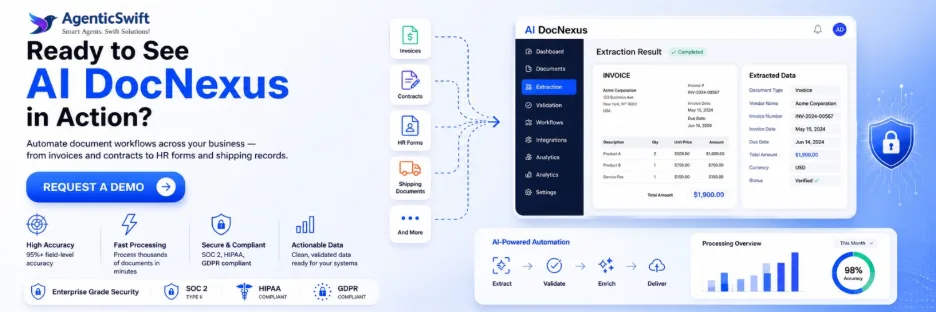
What AI DocNexus Does
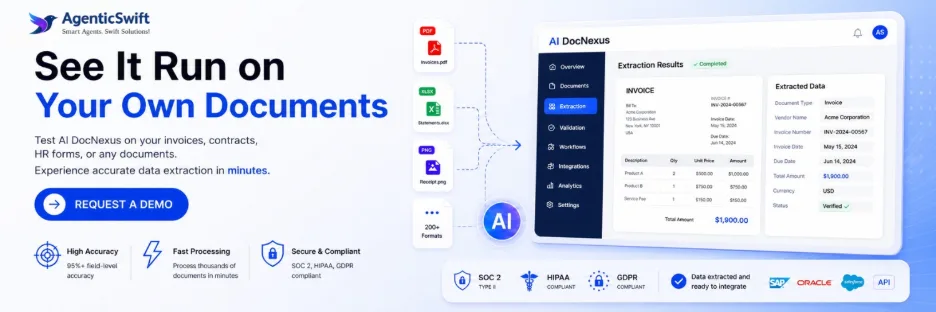
AI DocNexus is an enterprise AI document processing platform that ingests any document and outputs clean, structured data ready for downstream systems. Core functional scope:
- Document ingestion — accepts PDF, TIFF, PNG, JPG, DOCX, XLSX, HTML, EML/MSG, EDI X12, and scanned images via API, SFTP, email gateway, cloud storage watchers, and UI upload.
- Document classification — auto-identifies 200+ document types (invoice, PO, contract, passport, claim form, EOB, bill of lading, loss run, etc.) with 97%+ accuracy.
- Data extraction — pulls structured fields, line-item tables, handwritten content, checkboxes, signatures, and stamps.
- Semantic understanding — extracts meaning from unstructured text: governing-law clauses, diagnosis codes, liability caps, payment terms.
- Validation — applies business rules, master-data lookups, cross-document reconciliation, and anomaly detection.
- Delivery — pushes validated JSON/XML payloads into SAP, Oracle, Salesforce, Guidewire, Epic, and other enterprise systems via REST, webhook, or native connector.
Supported Document Types and Languages
AI DocNexus ships with pre-trained models for the document types enterprises most commonly process:
- Finance and procurement — invoices, purchase orders, receipts, remittance advices, bank statements, expense reports, tax forms (W-2, W-9, 1099, GST, VAT).
- Insurance — FNOL forms, ACORD forms, loss runs, policy schedules, broker slips, medical claim forms, EOBs, UB-04, CMS-1500.
- Banking and KYC — passports, driving licenses, national ID cards, utility bills, bank statements, loan applications, mortgage packages.
- Healthcare — discharge summaries, prescriptions, lab reports, radiology reports, prior auth forms, clinical trial documents.
- Logistics — bills of lading, airway bills, customs declarations, commercial invoices, packing lists, proof of delivery.
- Legal — master agreements, NDAs, amendments, lease agreements, SOWs, indemnity letters.
Language coverage: 50+ languages including English, Spanish, French, German, Italian, Portuguese, Dutch, Arabic, Hebrew, Hindi, Bengali, Tamil, Telugu, Chinese (Simplified and Traditional), Japanese, Korean, Thai, Vietnamese, Russian, and Turkish. Mixed-language documents are handled in a single pass.
How AI DocNexus Works
The platform runs a six-stage pipeline. Each stage is independently observable and individually tunable.
1. Intake and Pre-processing
- Auto-detects file type, decrypts password-protected files, and unpacks archives (ZIP, TAR, 7Z).
- Runs deskewing, denoising, binarization, and resolution enhancement for scanned images.
- Segments multi-document PDFs (a common issue with batch scans) into individual documents.
- Generates per-page confidence scores to surface unreadable pages before extraction.
2. Classification and Routing
- A fine-tuned vision-language classifier identifies document type and issuing entity (country of issue for IDs, carrier for insurance forms, tax jurisdiction for invoices).
- Routes each document to the extraction model tuned for that document type.
- Supports custom document types via 50–200 labeled samples for enterprise-specific forms.
3. Data Extraction
- Transformer-based vision-language model extracts field-level data, table rows, checkboxes, and signature zones in a single forward pass.
- Dedicated sub-models handle handwritten content (both cursive and print) and low-quality scans.
- Table extraction preserves multi-row, multi-page, and nested-header structures — important for loss runs, invoices, and medical bills.
4. Semantic Understanding
- Large language models interpret meaning: clause types in contracts, ICD-10/CPT codes in medical records, GL account mapping for invoice line items.
- Cross-field reasoning: if total = sum of line items, if date on document matches policy period, if claimant name matches policyholder.
5. Validation and Enrichment
- Business rules engine validates against enterprise master data (vendor database, customer list, policy register, product catalog).
- External lookups: VAT/GSTIN validity, sanctions lists, BIN/IFSC verification, address normalization.
- Confidence thresholds route low-confidence fields to a human reviewer through a streamlined web UI.
- Every correction flows back into the model as training signal — accuracy compounds over time on your corpus.
6. Delivery and Integration
- Outputs structured JSON or XML with per-field confidence scores and bounding-box coordinates linking back to the source document.
- Native connectors push data into SAP S/4HANA, Oracle NetSuite, Workday, Salesforce, Guidewire, Epic, ServiceNow, Microsoft Dynamics, Coupa, and Ariba.
- REST API, webhook events, Kafka streams, and SFTP drops for custom integrations.
Accuracy Benchmarks
Field-level accuracy on representative enterprise document corpora:
| Document Type | Field Accuracy | Straight-Through Rate |
| Structured invoices, receipts, POs | 98–99% | 92–96% |
| Semi-structured forms (KYC, claims) | 96–98% | 85–92% |
| Handwritten forms | 92–96% | 70–82% |
| Unstructured contracts | 94–97% | Review-assisted |
| Medical records and clinical notes | 93–96% | 75–85% |
| Tabular data (loss runs, itemized bills) | 96–98% | 88–94% |
With human-in-the-loop correction for low-confidence fields, end-to-end document accuracy routinely exceeds 99%.
Security, Compliance, and Deployment
Enterprise-grade controls and deployment options are native to the platform:
- Certifications — SOC 2 Type II, ISO 27001, HIPAA-aligned, GDPR compliant, with DPA available.
- Encryption — AES-256 at rest, TLS 1.3 in transit, customer-managed keys (BYOK) via AWS KMS, Azure Key Vault, or GCP KMS.
- Access control — SSO via SAML 2.0 and OIDC (Okta, Azure AD, Ping, Auth0), role-based access with field-level permissions.
- Audit logging — every action logged with actor, timestamp, and source-document provenance. Exports to SIEM platforms (Splunk, Datadog, Sumo Logic).
- Data residency — regions in US, EU, UK, Canada, India, Singapore, and Australia. No data leaves the chosen region.
- Deployment modes — multi-tenant SaaS, single-tenant private cloud on AWS/Azure/GCP, on-premise Kubernetes, and fully air-gapped installations for regulated or classified environments.
- PII handling — configurable masking, redaction, and retention policies per document type and field.
Integration Architecture
AI DocNexus is designed to plug into enterprise stacks without custom middleware:
- Accounts payable automation — invoice capture, three-way matching with PO and GRN, GL coding, and posting to SAP or Oracle. Typical outcome: 70% touchless processing, 50% faster cycle time.
- Insurance claims intake — FNOL digitization, document classification, reserving, and routing. Typical outcome: cycle time drops from 3–5 days to under 1 hour for simple claims.
- KYC and customer onboarding — ID verification, address proof extraction, sanctions and PEP screening. Typical outcome: onboarding time drops from 2–5 days to under 2 minutes.
- Loan and mortgage underwriting — income document analysis, bank statement parsing, property document review. Typical outcome: 40–60% reduction in underwriting turnaround.
- Contract intelligence — clause extraction, obligation tracking, expiry monitoring, and renewal management across contract portfolios.
- Medical claims adjudication — extracting diagnosis codes, procedures, and charges; cross-checking against policy terms and fraud indicators.
- Trade finance — letter of credit, bill of lading, and customs document processing for export-import workflows.
Implementation Timeline
A standard first-workflow deployment runs 10–12 weeks:
- Weeks 1–2: Corpus analysis on a representative sample. Baseline accuracy, edge-case identification, integration design.
- Weeks 3–6: Sandbox deployment with end-to-end integration to the target downstream system (ERP, claims, CRM).
- Weeks 7–10: Parallel run against existing process. Accuracy measured against ground truth; model tuned on client-specific corrections.
- Weeks 11–12: Production cutover with monitoring dashboards, defined SLAs, and exception-handling runbooks.
- Month 4+: Horizontal rollout. Subsequent workflows typically deploy in 4–6 weeks because infrastructure and integration patterns are in place.
Frequently Asked Questions
What is DocNexus?
AI DocNexus is an enterprise AI document parsing and automation platform by AgenticSwift. It extracts structured data from 200+ document types across 50+ languages using computer vision, transformer models, and LLMs — then delivers it into enterprise systems via API or native connector.
How does DocNexus work?
Through a six-stage pipeline: intake and pre-processing, classification and routing, AI extraction, semantic understanding via LLMs, validation against business rules and master data, and delivery into downstream systems. Every extracted field carries confidence scores and bounding-box provenance for audit.
Can DocNexus process unstructured documents?
Yes. Contracts, clinical notes, emails, and free-form narratives are handled natively through LLM-based semantic extraction, not template matching. This is a core differentiator from legacy OCR and rules-based IDP tools.
How accurate is DocNexus in data extraction?
Field-level accuracy ranges from 92% on handwritten content to 98–99% on structured invoices. With human-in-the-loop correction, end-to-end accuracy exceeds 99%. The platform improves continuously as it learns from corrections on your specific corpus.
Which industries can benefit from DocNexus?
Banking, insurance, healthcare, logistics, legal, manufacturing, and energy all run production workloads today. The common denominator is high document volume combined with operational, compliance, or customer-experience stakes.
The Bottom Line
Document workflows are the hidden operating tax on most enterprises. AI DocNexus by AgenticSwift AI replaces that tax with a platform that ingests any document, extracts clean data with measurable accuracy, and integrates directly with the systems that run your business — with the security, compliance, and deployment flexibility regulated enterprises require.
Book a personalized demo with AgenticSwift and receive a benchmark extraction report on a sample of your real-world documents within 10 business days.